If you Google for an explainer on the differences and use cases for the arithmetic mean vs geometric mean vs harmonic mean, I feel like everything you’ll find is pretty bad and won’t properly explain the intuition of what’s going on and why you’d ever do one or the other.
In fact, you sometimes will hear about someone choosing to use the geometric mean over the arithmetic mean because they want to put less weight on outliers– my position on this is that it should be criminal and punished with jail time and a life-time revocation of all software licenses.
Note that this blog refers to log() a lot. Every time I use log(), I am talking about the natural logarithm, never the log base 10.
TLDR: The Common Link
The arithmetic mean, geometric mean, and harmonic mean all involve the following four steps:
- Define some invertible function 𝑓(·)
- Apply this function to each number in the set: 𝑓(x)
- Take the arithmetic mean of the transformed series: avg(𝑓(x))
- Invert the transformation on the average: 𝑓-1(avg(𝑓(x)))
^ Given some function avg(x) = sum(x) / count(x). Or in more math-y terms, 
The only difference between each type of mean is the function 𝑓(·). Those functions for each respective type of mean are the following:
- Arithmetic mean: the function is the identity map: 𝑓(x) = x. The inverse of this function is trivially 𝑓-1(x) = x.
- Geometric mean: the function is the natural log: 𝑓(x) = log(x). The inverse of this function is 𝑓-1(x) = ex.
- Harmonic mean: the function is the multiplicative inverse: 𝑓(x) = 1/x. Similar to the arithmetic mean, the function is involutory and thus the inverse is itself: 𝑓-1(x) = 1/x.
We can also add the root mean square into the mix, which is not one of the “Pythagorean means” and is outside this article’s scope, but can be described the same way using some 𝑓(·):
- Root mean square: the function is: 𝑓(x) = x2. The inverse of this function is 𝑓-1(x) = √x
And I leave as an exercise to the reader to define the “f(x)” of mean kinetic temperature, another mean formula that can be expressed as some 𝑓-1(avg(𝑓(x))).
This means that:
- The geometric mean is basically exp(avg(ln(x))).
- The harmonic mean is basically 1/avg(1/x)).
We’re playing fast and loose with the math notation when we say that, but hopefully this makes perfect sense to the Pandas, R, Excel, etc. folks out there.
Another way of thinking about what’s happening: Each type of mean is the average of 𝑓(x), converted back to the units x was originally in.
In fact, you can imagine many situations in which we don’t care about the conversion back to the original units of x, and we simply take avg(𝑓(x)) and call it a day. (Later in this article we will discuss one such example.)
Basically, instead of thinking about it as arithmetic mean vs geometric mean vs harmonic mean, I believe it is far better to think of it as deciding between taking a mean of x vs log(x) vs 1/x.
If someone tells you “I took the geometric mean of x,” you should translate it as “I took the mean of log(x), then converted it back to the units of x.”
If someone tells you “I took the harmonic mean of x,” you should translate it as “I took the mean of 1/x, then converted it back to the units of x.”
𝑓(x) for the Geometric Mean
The geometric mean is basically just exp(avg(ln(x))) for some series x. You may be thinking to yourself, “hold on just a second, that’s not the formula I learned for geometric means, isn’t the geometric mean multiplicative?” Indeed, the geometric mean is usually defined like this:
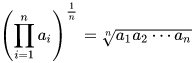
The multiplicative formulation of the geometric mean is a big part of my complaint on how these things are taught and is a big motivation for why I wrote this blog post. This formulation has two problems:
- It does not provide a good intuition for the relationship between all the types of means.
- It does not provide a good intuition for when this type of mean is useful.
Let’s start with a slightly easier, non-geometric example to understand our motivation for why we want to use the geometric mean in the first place. Then we will move toward understanding why we prefer the formulation that uses logarithms.
Imagine a series xi that starts at x0 = 42, and each innovation in the series is the sum of the previous value plus a random variable sampled from a normal distribution: Δx ~ N(1, 12):
The output:
>>> import numpy as np
>>> np.random.seed(42069)
>>> x = 42 + np.random.normal(1, 1, size=100).cumsum()
>>> print(x)
[ 42.92553097 43.49170572 44.8624312 46.51825442 48.63784536
48.8951176 50.54671526 51.22867236 50.3424614 52.75737276
51.69855546 52.65819763 54.06775613 53.28172338 53.66697074
56.12498604 57.61778804 58.27503826 57.70256389 59.38735085
60.22063766 61.90920957 63.79519213 64.69549338 64.43602456
67.30519201 67.13024514 67.78104984 69.06629574 69.60412637
71.16176743 71.62132034 74.39080503 77.09848795 79.4652772
80.39650678 80.91626346 81.52066251 82.33636486 81.91222599
83.48843792 85.30007755 86.06519214 86.43031374 87.13039204
90.25620318 93.03419293 94.51869434 95.27790282 95.90321776
96.76434325 98.1029641 98.32628988 98.49971699 97.59649203
99.94065695 103.04571803 102.67171363 103.76771164 103.59085332
105.19872315 107.13508702 109.37005647 110.2144704 112.2378265
113.62732814 114.72603068 115.62444397 115.05362115 115.76635685
116.1258608 117.39540806 119.84769791 120.87730939 121.77746089
121.28436228 123.23558472 124.28775198 123.13780385 123.70222487
124.66368608 126.87138039 127.04262872 127.67170174 128.37581743
131.53389542 130.40204315 132.71405898 135.27380666 136.73629043
136.92096472 136.91655098 139.62076843 140.17345403 141.37458494
141.97151287 142.00637033 143.79217108 143.55446468 143.82917616]
On average, this series increments by 1, or: Δx̄ = 1. The code example with N=100 is fairly close to this:
>>> print(np.diff(x).mean())
1.019228739283586
A nice property of this series is that we can estimate the number xi at any point out by taking x0 and adding i*Δx̄:
xi ~= x0 + i * Δx̄
For example, given x0 = 42 and Δx̄ = 1, we expect the value at i = 200 to be: x200 = 42 + 1 * 200 = 242.
One more note is, you can see if we did this with Δx ~ N(0, 12), the end value would be pretty close to our starting value, since on average the change is 0 so it doesn’t tend to go anywhere:
>>> y = 42 + np.random.normal(0, 1, size=100).cumsum()
>>> print(y)
[42.14327609 41.73220144 40.34751605 39.89921679 40.71819255 39.98666041
39.99145178 38.64581255 39.41370336 38.25513447 38.30145859 39.42274649
38.04648615 36.24137523 35.46375047 35.50439808 36.63500785 36.59388467
37.57533195 39.08275764 41.53667158 41.56685919 41.41477371 41.2577686
41.07551212 42.30114276 41.64867131 42.72961065 43.64169298 42.34088469
42.88702932 42.23553899 43.61890447 43.82668718 41.60184273 40.27826271
41.25916824 42.18715753 41.85738733 41.14549348 41.84768201 41.69063447
40.6840706 40.83319881 40.40445944 39.34640317 38.09054094 38.87652195
40.3595753 40.8148765 40.83529456 41.18929838 40.08415662 39.05557295
38.64264682 36.52039689 36.69964053 35.37000166 35.20584305 36.37476645
36.88307023 37.31826077 38.29526266 37.74575645 36.80800914 37.5450178
38.65961874 38.88282908 39.928218 40.56804189 41.80931894 42.89032324
42.04655778 42.18207305 44.03568325 44.30914736 43.87061869 42.66411857
41.56574674 42.80970406 44.62550963 44.68844778 44.39159728 44.83927878
43.25006607 42.00114961 42.34021689 41.85862954 41.12647006 42.40091559
41.94186999 42.49949258 40.68446343 40.00669043 39.43730559 39.77142686
39.78884967 40.82806017 40.40149929 40.08320282]
Now imagine instead that we’re working with percentages. Let’s try to create a series that acts as a percentage, but doesn’t drift anywhere i.e. its average percent change is 0. A sensible thing to do here is to set the mean of the normal distribution to 1.00 because 42 * 1 * 1 * 1 * 1 * 1 * 1 * … = 42. If we do that (and set the variance to be small), then take the cumulative product, we get this:
>>> z = 42 * np.random.normal(1.00, 0.01, size=100).cumprod()
>>> z
array([42.29485307, 42.10421377, 41.92718004, 42.15880536, 42.40603275,
42.01686461, 41.69826372, 41.83495864, 41.25095708, 41.10461977,
41.49515729, 41.69517539, 41.32604793, 40.91920303, 40.79499964,
40.35644085, 40.20518116, 40.1654621 , 39.74730232, 39.78929327,
40.12100013, 40.02502775, 39.44923442, 39.44081756, 39.4641928 ,
38.80762578, 38.89268137, 39.11465487, 39.16728902, 39.76985309,
40.06795117, 40.23589703, 40.10532389, 39.34583711, 39.61553391,
39.9075052 , 40.10830292, 39.9106884 , 39.85976268, 39.79411555,
38.99997783, 39.44369954, 40.39200402, 40.88128515, 40.44479728,
40.22209045, 40.0285552 , 40.23540308, 40.42241127, 40.9433428 ,
41.24621725, 40.8689337 , 41.29192764, 40.56362479, 41.17267844,
40.51011262, 40.87376187, 40.39144992, 39.75819826, 40.0730663 ,
40.58474266, 40.38275682, 40.37280631, 40.23939867, 40.63397416,
41.09796335, 41.35882045, 41.51904402, 41.34215026, 40.6133968 ,
40.66670512, 40.23359742, 40.02866379, 38.7808683 , 39.19549234,
38.93472017, 38.95480154, 38.62374928, 38.76198573, 38.75981943,
38.8845329 , 39.13893181, 38.41712861, 38.51901389, 38.70939761,
39.17713543, 38.85041645, 38.54570443, 38.93457566, 39.1375754 ,
39.2318531 , 39.14232187, 39.11531491, 38.02500266, 38.77757832,
38.9453628 , 38.19591922, 37.34626113, 38.13230149, 37.96815914])
Oh dear, clearly the number is drifting downwards. Even though our normal distribution has a mean of 1.00, the percentage change is negative on average!
The reason why this happens is pretty straightforward: If you multiply a number by 101% then by 99%, you get a smaller number than you started with. If you do this again and then again a third time, the resulting number gets smaller and smaller even though (1.01 + 0.99 + 1.01 + 0.99 + 1.01 + 0.99) / 6 = 1.00.
Curious minds will be asking a few questions that are all variants of: What thing allows us to input a “0%” and allows us to have a series that actually, truly increases on average by 0% over time?
In the example of 101% and 99%, really what we needed to be doing is oscillate between 101.0101010101% and 99%, and this gives us an average percentage change over time of 0%. The formula that represents this is the geometric mean:
(0.99 * 1.01010101010101)^(1/2) = 1.00000
We can intuit here that the reason this works is because:
- Percentages are multiplied.
- Geometric means are like the multiplicative equivalent of the arithmetic mean.
- Ergo, geometric means are good for percentage changes.
That’s all fine and dandy. But I would argue this approach is not the best way to think about it.
Just Use Logarithms
There is a much better way to think about everything we’ve done up to this point on geometric means, which is to use logarithms. Logarithms are, in my experience, criminally underused. Logarithms are a way to do the following:
- turn multiplication into addition
- turn exponentiation into multiplication
And we can see that the formula for the geometric mean consists of two steps:
- Multiplication of all x0, x1, … followed by:
- Exponentiation by 1/N
If we were to instead use logarithms, it would become:
- Addition of all log(x0), log(x1), … followed by:
- Multiplication by 1/N
Well golly, that looks an awful lot like taking the arithmetic mean.
We can just use the above example to confirm this works as intended:
(log(0.99) + log(1.01010101010101)) / 2 = 0
Of course, the final step to a proper geometric mean is that we need to convert back to the original domain, so let’s take the exp() of the arithmetic average of log(x), and we’re all set. (That said, we could also skip this final step, but more on that later.)
e^((log(0.99) + log(1.01010101010101)) / 2) = e^0 = 1
It would be negligent of me if I failed to point out another factoid here, which is that the example where we used a normal distribution and cumulatively multiplied it on the number 42 was pretty bad. What we should have been doing is something like this:
>>> np.random.seed(123789)
>>> w = np.exp(np.log(42) + np.random.normal(0, 0.01, size=100).cumsum())
>>> print(w)
[42.04757853 42.03767307 41.71175204 41.35454934 41.62054759 41.6075732
41.54983288 41.43970185 41.91568309 42.23240569 42.72341859 42.24791181
41.97051688 41.99435579 42.04788319 42.68784402 43.17163141 43.11321422
43.05973883 43.48593847 43.45580668 43.67426001 44.5840072 45.69515896
46.29346244 46.52853533 46.2992428 46.18620244 45.88003251 46.62132714
46.60257292 46.43310272 46.55999518 46.32343379 46.20800647 45.89207742
46.00097075 46.18218262 46.59929002 46.35029673 46.24973082 46.39807618
46.924215 46.94728105 46.5494736 46.43645126 47.26412466 46.54322008
46.33447728 46.63572133 46.6786372 46.90368576 47.21667417 47.05015934
47.01905637 47.43071786 47.57165118 46.9620617 47.2683152 46.28069134
46.20036235 45.76285665 46.12441204 46.58868319 46.32119959 46.33432096
46.83187783 46.486633 46.84950368 47.20823273 46.80124992 47.08130145
46.58325664 46.71110628 46.81578114 46.14625089 46.15792567 45.85668589
45.37720581 44.64861972 44.39836865 43.93450417 45.0169601 45.58411068
45.28835317 45.33707393 45.25037578 45.52754206 45.26391821 45.28384832
45.06173788 45.5085144 45.63230275 44.99180853 45.43820589 46.09319298
46.01279547 46.08962901 46.67943336 46.96112588]
Keeping in mind that ln(1) = 0, and again that logarithms turn multiplication into addition, so we can just use the cumulative sum this time (rather than the cumulative product).
Note that in this formulation, the series is no longer normally distributed with respect to x. Instead, it’s log-normally distributed with respect to x. Which is just a fancy way of saying that it’s normally distributed with respect to log(x). Basically, you can put the “log” either in front of the word “normally” or in front of the “x”. “Log(x) is normal” and “x is log-normal” are equivalent statements.
The code above may look like a standard normal distribution, but you know it’s log-normal because (1) 42 was wrapped in log(), and (2) I end up wrapping the entire expression in exp().
When working with percentages, we like to use logarithms and log-normal distributions for a few reasons:
- Log-normal distributions never go below 0. Logarithms never go below zero in their domain. If we used, say, a normal distribution, there is always a chance the output number is negative, and if we mess that up things will go haywire.
- The average of the series for log(x) equals the μ (“mu”) parameter for the log-normal distribution. Or rather, it may be more accurate to say that for any finite series that is log-normally distributed, the mean of that series is an unbiased estimator for μ.
- Adding 2 or more normally distributed random variables together yields another normally distributed variable, but the same is not true when multiplying 2 or more normally distributed random variables. So if we use logs, we get to keep everything normal, which can be extremely convenient.
- Adding is easier than multiplying in a lot of contexts. Some examples:
- In SQL, the easiest way to take a “total product” in a
GROUP BYstatement is to doEXP(SUM(LN(x))). - In SQL, the easiest way to take the geometric mean in a
GROUP BYstatement is to doEXP(AVG(LN(x)))(but you already knew that, right?). - Linear regression prediction is just adding up the independent variables on the right-hand side, so estimating some
log(y)using linear regression is a lot like expressing all the features as multiplicative of one another.
- In SQL, the easiest way to take a “total product” in a
- It just so happens that in a lot of contexts where percentages are an appropriate way to frame the problem, you’ll see log-normal distributions. This is especially true of real-world price data, or the changes in prices: log(pricet) – log(pricet-1). (Note if log(price) is normal, that means subtracting two log(price)’s is normal, because of the thing about adding two normal distributions.) Try a Shapiro-Wilk test on your log(x), or just make a Q-Q plot of log(x) and use your eyes.
- log(1 + r) (with the natural log) is actually a pretty close approximation to r, especially for values close to 0.
Two more things– first, you can always us the np.random.lognormal() function then take the cumulative product to confirm your high school pre-calculus:
>>> w = 42 * np.random.lognormal(0, 0.01, size=100).cumprod()
>>> print(w)
[42.04757853 42.03767307 41.71175204 41.35454934 41.62054759 41.6075732
41.54983288 41.43970185 41.91568309 42.23240569 42.72341859 42.24791181
41.97051688 41.99435579 42.04788319 42.68784402 43.17163141 43.11321422
43.05973883 43.48593847 43.45580668 43.67426001 44.5840072 45.69515896
46.29346244 46.52853533 46.2992428 46.18620244 45.88003251 46.62132714
46.60257292 46.43310272 46.55999518 46.32343379 46.20800647 45.89207742
46.00097075 46.18218262 46.59929002 46.35029673 46.24973082 46.39807618
46.924215 46.94728105 46.5494736 46.43645126 47.26412466 46.54322008
46.33447728 46.63572133 46.6786372 46.90368576 47.21667417 47.05015934
47.01905637 47.43071786 47.57165118 46.9620617 47.2683152 46.28069134
46.20036235 45.76285665 46.12441204 46.58868319 46.32119959 46.33432096
46.83187783 46.486633 46.84950368 47.20823273 46.80124992 47.08130145
46.58325664 46.71110628 46.81578114 46.14625089 46.15792567 45.85668589
45.37720581 44.64861972 44.39836865 43.93450417 45.0169601 45.58411068
45.28835317 45.33707393 45.25037578 45.52754206 45.26391821 45.28384832
45.06173788 45.5085144 45.63230275 44.99180853 45.43820589 46.09319298
46.01279547 46.08962901 46.67943336 46.96112588]
Second, we might as well take the geometric mean of the deltas in the series, huh?
We expect that the geometric mean should be very close to 1.00, so when we subtract 1 from it we should see something very close to 0.00:
>>> np.exp(np.diff(np.log(w)).mean()) - 1
0.0011169703289617416
Additionally, we expect the geometric mean to be pretty close (but not equal) to the arithmetic mean of the percentage changes:
>>> (np.diff(w) / w[:-1]).mean()
0.001156197504173517
Last but not least, in my opinion, if you are calculating geometric means and log-normal distributions and whatnot, it is often perfectly fine to just take the average of log(x) rather than the geometric mean of x, or the normal distribution of log(x) instead of the log-normal distribution of x, things of that nature.
In a lot of quantitative contexts where logging your variable makes sense, you will probably just stay in the log form for the entirety of your mathematical calculations. Remember that the exp() at the very end is just a conversion back from log(x) to x, and sometimes that conversion is unnecessary! Get used to talking about your data that should be logged in its logged form.
In that sense, I mostly feel like a geometric mean is just a convenience for managers. We tell our managers that the average percentage change of this or that is [geometric mean of X minus one] percent, but in our modeling we do [mean of log(X)]. Honestly, I prefer to stick with the latter.
Re-contextualizing the Canonical Example of the Harmonic Mean
The most common example provided for a harmonic mean is the average speed traveled given a fixed distance. Wikipedia provides the example of a vehicle traveling 60kph on an outbound trip, and 20kph on a return trip.
The “true” average speed that was traveled for this trip was 30kph. The 20kph needs to be “weighted” 3 times as much as the 60kph part because traveling a fixed distance at 3 times slower the speed means you’re traveling at that speed for 3 times as long because that’s how much longer it takes you to travel that distance. You could take the weighted average to get to this 30kph number, i.e. (20*3+60)/4 = 30. That works for mental math. But the more generalized way to solve this is to take reciprocals.
Given what we now know about the harmonic mean, we can see that what we are doing is:
- Convert the numbers to hours per kilometer: 𝑓(x) = 1/x
- Take the average of hours per kilometer.
- Convert back to kilometer per hour: 𝑓-1(x) = 1/x
Our motivation for this is because we want a fixed denominator and a variable numerator so that the numbers we’re working with work sensibly when being added up (e.g. a/c + b/c = (a+b)/c). In the original formulation where the numbers are reported in kilometers per hour, the denominator is variable (hours) and the numerator is fixed (kilometers).
Again, much like the geometric mean situation, our motivation in this case is to make the problem trivially and sensibly additive by applying an invertible transformation. Note that if the duration was variable but the time was fixed, then the numbers would already be additive and we would just take the average without any fuss.
Why Use Means in the First Place?
It may sound silly to even ask, but we should not take for granted the question of why we use means and whether we should be using them.
For example, imagine a time series of annual US GDP levels from 1982 to 2021. What happens if you take the mean of this? Answer: you get $11.535 trillion. OK, so what though? This value is not going to be useful for, say, predicting US GDP in 2022. US GDP in 2022 is more likely to be closer to the 2021 number (23.315 trillion) than it is to be anywhere near the average annual GDP between 1982 and 2021. Also, this number is extremely sensitive to the time periods you pick.
Clearly, it is not necessarily the case that taking an average of any and all data is useful. Sometimes (like in the above example) it is pretty useless.
Another example where it may be somewhat useful but misleading would be for household income. Most household income statistics use median household income, not mean household income, because these numbers are heavily skewed by very rich people.
To be clear, sometimes (arguably a majority of the time) it’s fine to use the mean over a median, even if it is skewed by a heavy tail of outliers! For example, insurance policies: the median payout per fire insurance policy is a very useless number– it’s almost assuredly $0. But you can’t price with that! Your insurance company will live and die based on means, not medians!
The only reason in the household income context is because we want to know what a typical or representative household is like, and the mean doesn’t give us a great idea of that due to the skew. Similarly, in the fire insurance case, a typical household with fire insurance gets a payout of $0. But the thing is we don’t actually care about typical or representative households doing our actuarial assignment, that’s not what insurance is about.
In the case of the GDP example, the mean was useless because the domain over which we were trying to summarize the data was a meaningless and arbitrary domain, and the data generating process is non-stationary with respect to that domain. Taking the median also would have been pretty useless, too, which is to say none of these sort of summary statistics are particularly useful for this data. In the household income example, we want some sort of summary statistic, but we want every household at the top to offset every household at the bottom, hit for hit, until all that’s left is the 50th percentile.
In short:
- For some data, neither mean or median is useful.
- Sometimes mean is useful and median is not.
- Sometimes median is useful and mean is not.
- Sometimes they’re both useful.
- No, the median is not something you use just to adjust for skew (because sometimes you don’t want to adjust for skew, even for very heavy-tailed distributions). There are no hard and fast rules you can make based on a finite distribution’s shape alone. It all depends on the context!
OK, But Really, Why Use Means? (This Time With Math)
One reason we like to use means is because of the central limit theorem. Basically, if you have a random variable sampled from some stationary distribution with finite variance, the larger your sample gets, the more the sample mean (which is itself a random variable) converges to a normal distribution with mean equal to the population mean.
The central limit theorem is often misunderstood, and it’s hard to blame people because it’s a mouthful and it’s easy to conflate many of the concepts inside that mouthful. There are two distinct mentions of random variables, distributions, and means.
If more people understood the central limit theorem you’d see fewer silly statements out in the wild like “you can’t do a t-test on data unless it’s normally distributed.” Ahem… yes you can! The key here is that distribution of the underlying data is different from the distribution of the sample mean. And it only takes a modest sample size for the distribution of a sample mean to converge to normality, even when the underlying data is non-normal. One way to think of the central limit theorem is that it is saying “more or less all arbitrary distributions of data have a sample mean that converges to a normal distribution.” It’s not saying the underlying data is normal, it’s saying the sample mean is itself a random variable that comes from its own distribution, which converges to normality.
This serves as our first motivation for why we care about means: all finite-variance stationary distributions have them, they are pretty stable as the sample size increases, and they converge to their population means.
A second motivation is because the arithmetic mean minimizes the squared errors of any given sample. And sometimes that’s pretty useful. That is to say, if you have some sequence xi of N numbers x1, x2, x3… xN, and you pick some number y, the y that minimizes 

A third motivation is because in many contexts, the mean gives us an estimator for a parameter we care about from an underlying distribution. For example:
- The sample mean of a normally distributed random variable x converges to the mean parameter for that distribution.
- The sample mean of a normally distributed random variable log(x) converges to the mean parameter of a log-normal distribution of x.
- The sample mean of the centered squares (
) of a random variable x converges to a biased (but correctable) estimate of the distribution’s variance.
- The sample mean of a Bernoulli distributed random variable x converges to the probability parameter of a Bernoulli distribution.
- Given some r, the sample mean of a negative binomial distributed variable x, when divided by r, converges to the odds of the probability parameter p.
So by taking a mean, we can estimate these and many other distributions’ parameters.
Final Notes
- I find the statement that “arithmetic mean > geometric mean > harmonic mean” to be a cute factoid but often worse than useless to point out, which is why it’s down here. It’s way more often than not inappropriate to compare means like this. It either is or isn’t appropriate to take reciprocals before averaging, or take the log before averaging. The comparison of magnitudes across these means is completely irrelevant to that decision, and this cute factoid may mislead people into thinking that it is.
- I think technically one reason the geometric mean is often defined using power and multiplication, rather than logs and exponents, is because you are technically allowed to use negative numbers? However, I am not aware of any actual situations where a geometric mean would be useful but we’re allowing for negative numbers.

You must be logged in to post a comment.