
There are endless blog posts out there describing the basics of linear regression and penalized regressions such as ridge and lasso. These are useful resources, and I’m happy they exist to level the playing field both for people not in college and for people who don’t have the time or fortitude to trudge through mountains of math merely to get your computer to draw a line through some data on a scatterplot.
I’m not interested in providing Yet Another Tutorial on how to execute basic regression functions in programming languages like Python. I am however interested in filling in some very important gaps not typically covered by the aforementioned learning resources. If you learned from such tutorials, then this post is for you.
My goal with this post is hopefully to provide more intuition about linear models, including what exactly is happening when you run a regression, how to transform data for these regressions, and what you can and can’t do with certain types of regressions.
Although this post is primarily aimed at people who learned most of what they know from online tutorials, it also should be of use to people who want to brush up on concepts not typically encountered in a data scientist’s day-to-day, and to educators who want a reference for things their students might not know.
For those who would rather skip around, here is a table of contents for this post:
- Linearity is not that restrictive of an assumption.
- How do independent variables interact with one another in a regression?
- Conceptualizing linear regression as a system of equations (instead of one single equation).
- What’s the easiest way to understand why and how lasso and ridge behave differently?
- Can penalized parameters be used for causal inference?
Linearity is not that restrictive of an assumption.
Recently I came across a video providing a quick tutorial of nonlinear regression. The person doing the video opened with the following example:

I want to be perfectly and totally clear: The above model is linear. You can and in fact should use linear regression to solve this. All you need to do is create two more columns in your data–one being the reciprocal of x, and another being the natural log of x–and include those as features in your regression. If you use a nonlinear model to solve this, I will sneak into your house at night and uninstall Python and R off your computer.
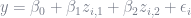


The point here is that linear models do not require that all the variables in your data are explicitly linear. All that is required is that each term can be expressed linearly, i.e. a summation of parameters multiplied by some variable. You can easily accomplish this by “preprocessing” your data in machine learning terms, or “not being lazy” in statistics terms.
I’m sorry for being a little sassy about this. And I’ll be real with you: the truth is it’s not always as easy as “just transform the data to a linear form” because you don’t always know what the underlying process for your data is. In those cases where the data generating process is unknown, it can be hard to tell if your data can be transformed into a linear model in a way that makes sense. It requires some creativity and elbow grease, and sometimes it doesn’t pay off.
But on the flip-side, too often the default mode of thinking is to see nonlinear data and assume the model should therefore be nonparametric or nonlinear instead of thinking about whether the data can or should be transformed into a linear model. All I’m asking of people is to consider that the latter is also a great option!
In fact, all of the following seemingly nonlinear functions can be estimated with a linear regression and proper data transformations:
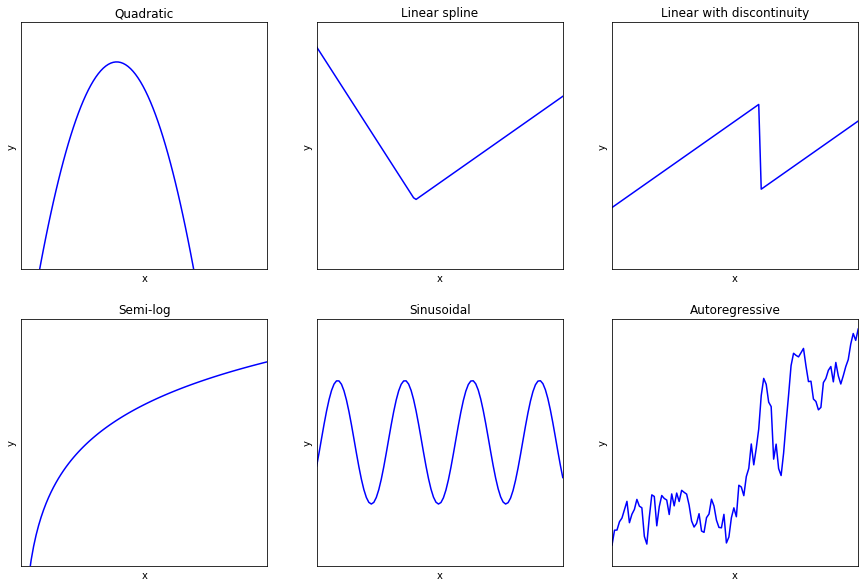
Note that some of these functional forms:
- Make certain assumptions about the error term (e.g. semi-log form models assume that errors are multiplicative in the exponential form, and are only additive in the semi-log form);
- Require large-sample asymptotic properties for consistent estimates (e.g. autoregressive processes, which are not strictly exogenous);
- Require tuning a hyperparameter (e.g. splines and discontinuities require finding where the disjointed component is; autoregressive processes require tuning the number of lags);
- Require additional testing (e.g. the autoregressive process might have a unit root);
- Cannot be combined cleanly with other methods (e.g. autoregressive terms with fixed effects produce very biased parameters with OLS).
But none of this data requires you to deviate from OLS, as long as you are willing to transform your data. For example, fitting quadratic data simply means making a new column in your data that is 

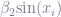
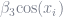
How do independent variables interact with one another in a regression?
A friend of a friend asks this question in the job interviews they conduct: “If you add a new variable to a [unpenalized] linear regression, and one of the other parameters changes, what does that indicate about the variables?”
Believe it or not, some otherwise smart people can’t answer this question, even though the question is fundamental to data modeling in general. I suspect one reason why is because machine learning techniques let you avoid considering this question in the day-to-day. At worst, adding more variables does nothing to improve the predictive accuracy of your model and can only make your model predict better. Some ML methods do the feature selection for you, and often in ML you often don’t look at or really care about the parameters. So it’s easy to forget how they work.
The simple answer to this question is that a change in one of the other parameters means the variables are correlated (geometrically, you could say that the variables are not orthogonal).
The less simple answer to this question is the Frisch-Waugh theorem.
Back in the stone age, before computers were blazing fast, calculating regressions took a very long time. This had various implications. First, it was important you knew every single detail about the regression you’re calculating before you do one–you only got one regression, and it had to count! Second, understanding the properties of OLS and regressions was extremely important because some of those insights could make your job a lot easier. Instead of taking two weeks to calculate one regression, maybe a little trick could make it take one week instead. Furthermore, you had to actually do abstracted mathematics to derive those properties instead of brute-forcing your way into those insights because, you know, there were no computers.
One question you might have been concerned about back in ‘ye olde days was the question of which is better:
- Detrending each variable (i.e. removing the time-related component from each variable) then performing a regression on the detrended variables.
- Adding time as a variable to your model without detrending.
In 1933, Ragnar Frisch and Frederick Waugh proved that these are actually the same thing (as far as your not-time-related parameters are concerned). In other words, including time as a variable detrends the other parameters. Hooray, now calculating regressions is marginally easier without blazing fast computers! (Michael C. Lovell generalized this theorem to all subsets of variables, not just time trends, and so the theorem is sometimes called the Frisch-Waugh-Lovell theorem.)
Frisch-Waugh is basically a microcosmic version of the geometric intuition that OLS orthogonally projects 
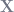
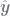
In slightly less jargony terms: each column of
Conceptualizing linear regression as a system of equations (instead of one single equation).
Did you know that 
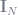
This so-called “pseudo-inverse” of X can be found in the OLS estimate, 
Do you remember solving systems of linear equations in high school precalculus? Or college linear algebra? At first you do the equations by hand, perhaps with the Gauss-Jordan algorithm. Then you learn that there is a matrix form of the system, 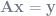
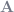
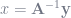
Look familiar? Yep, the OLS estimator is simply your feature space (pseudo-)inverted then multiplied by the dependent variable vector.
Anyone who uses Matlab (godspeed, you brave souls) is already intimately familiar with this: in Matlab, you don’t solve OLS with a function called “regression” or anything like that. Instead, to solve for Xb=y, you “divide” 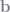
b = y\X (\ is dividing from the left, / is dividing from the right). (See footnote 3.)
This is a very different way of thinking about OLS than you’re probably used to if you’re using R, Python, or Stata, which is precisely why I’m bringing this up. In most statistical programs, we think of 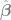

In the way that Matlab frames the problem,
This is not always the best way to conceptualize linear regression, but it’s important to have it in your toolkit. For example, understanding this way of thinking can help you better conceptualize other statistical methods such as the generalized method of moments, which (at least for me, personally) makes more sense with the “system of linear equations” framing.
What’s the easiest way to understand why and how lasso and ridge behave differently?
Lasso and ridge are two ways to add penalization (a way to regularize your model, i.e. reduce variance and increase bias) to a linear model. The mathematical difference between lasso and ridge is pretty straightforward: lasso penalizes by the sum of the absolute values of the parameters; ridge by the sum of squares). However, thinking about the implications of this behavior can be tricky, and isn’t often clearly explained.


The most useful way to think about lasso and ridge in general is to think about extremes. For example, when the penalty 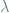
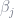
As for the differences between ridge and lasso, you can also think about those in terms of extremes. For example, think of all the points where the penalty term is some constant, 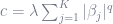
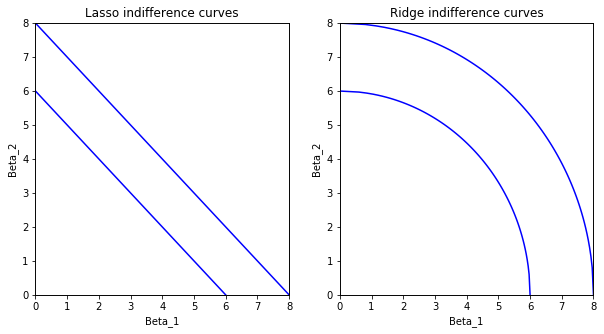
Note with ridge regression how the slope changes: On the uppermost curve, as 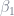
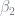
Lasso does not behave like this. Going from
The only question remaining is: how do you choose between ridge and lasso? Honestly, I’m not so sure myself. Some would argue the real answer to this question is to just use elastic net, which is essentially a middle ground between ridge and lasso, but without compromising lasso’s feature selection property. (See footnote 4.) Worst comes to worst, when tuning the 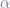
Can penalized parameters be used for causal inference?
Penalized regressions (ridge and lasso) will predict better out of sample than plain ‘ol ordinary least squares because of the bias-variance trade-off. The TLDR is: totally unbiased estimates have more variance, which means they are more sensitive to fluctuations in the data you ran the model on. So when it comes time for the model to “see” previously unseen data, that higher variance can cause your model to be a bit off. If you are not regularizing your predictive models (via penalization, in the case of linear regression), then you are probably doing something wrong.
Based on that fact, it seems unintuitive to suggest that although penalized parameters are superior for predictive purposes, they’re also inferior for causal inference. After all, if penalization makes the model fit better out of sample, doesn’t that mean it’s the more “correct” model? And isn’t a more “correct” model better for all purposes–including inference?
This seems to be the view of some data science trolls in my Twitter mentions who keep telling me that no regression should ever be left unpenalized. And it is–in a word–wrong.
In more than one word: there are two ways to think about why penalized parameters cannot be used for causal inference.
The first way to think about this is similar to the intuition behind omitted variable bias (OVB). Imagine that we’re measuring wages (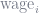
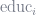

But what if wage and educ both correlate with something not included in the regression equation, such as innate skill (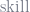
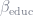
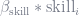
What does this have to do with penalization? Well, let’s say you find a way to accurately measure skill and include it in your regression, alongside 10 other variables, but then you penalize the model. Penalization will tend to favor variables that correlate with other independent variables: if one variable can account for most of the variation but also correlates with other variables (let’s say, for example, 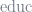
UPDATE [December 6, 2019]: I had been meaning to make this update for a while, but I had put it off until now. A previous version of this post referenced two arguments for why causal inference requires unpenalized parameters. The first of these arguments (OVB) is, as far as I can tell, sound, and can be read above. The second argument was fallacious, and has since been removed. The second argument’s flaw was that it effectively said that parameters should not only be norm-unpenalized, but made unbiased in general. Bias and norm-penalization are not interchangeable, and as such, I fell into a trap. An estimator, even a causal one, can make a trade-off between precision and accuracy, and it may be the case you can find a biased estimator that has a lower mean squared error than an unbiased one, and that estimator may be preferable in some cases.
Footnotes
Footnote 1
Recall that 
predict() function to calculate predicted values of y (i.e. y-hat, or 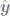
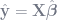
Finding the best fitting values of your linear regression is a “projection” of 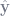
A projection is any linear transformation that is “idempotent.” A transformation matrix that is “idempotent” is one where 
When we combine the equations for the OLS estimate 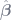

The matrix that explicitly gets you from y to y-hat has a special name: (you guessed it) the projection matrix, 
The concept of the projection matrix and its cousin, the annihilator matrix 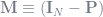
Footnote 2
Frisch-Waugh is commonly taught in econometrics and statistics by name, ultimately to inform some of the algebraic intuition behind omitted variable bias. The Elements of Statistical Learning (TESL), a machine learning textbook, effectively teaches Frisch-Waugh’s intuition without actually calling it such, and the way it does so is pretty cool! Instead of splitting 
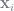

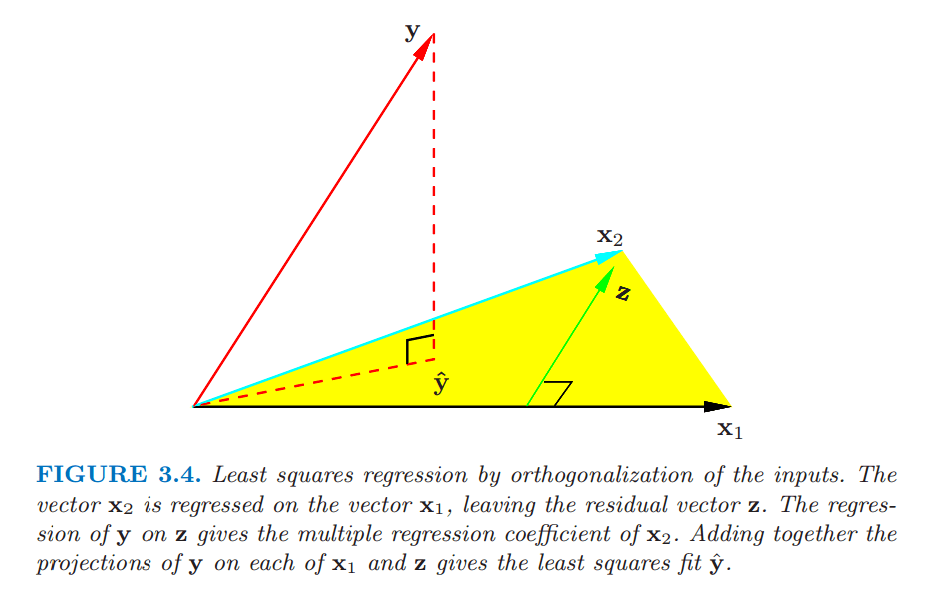
Footnote 3
Note that even in Matlab, no pseudo-inversions are being explicitly calculated to get your OLS solution, since that would take way too long. Matlab uses the QR decomposition 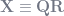
Footnote 4
I expressed penalization generally as 


You must be logged in to post a comment.