The last time I wrote about a specific interview problem, I admired the problem for being really cool and challenging, but complained about how the salary was not proportional with the difficulty of the problem.
I have no such complaints this time around. This latest problem was for a job with a solid base salary and an impressive salary range, which was wide open to accommodate everyone from PhD’s to people with bachelor’s degrees. This problem was, if anything, on the easy side relative to the salary. It was also relevant to the job’s daily functions.
Good interview problems are partly context dependent, and this one hit all the nails on their heads. You can enjoy this problem without the guilty conscience of knowing it’s being used to recruit people who will be underpaid.
This problem isn’t that hard, but it’s not that easy either. I’d expect anyone working with data to be able to solve this problem in the language of their choice given a reasonable amount of time. That said, SQL provides for the most intriguing solutions.
Here it is:
The Problem
You have a table of trading days (with no gaps) and close prices for a stock.
CREATE TABLE stock (
trading_date DATE UNIQUE,
price FLOAT
);
Find the highest and lowest profits (or losses) you could have made if you bought the stock at one close price and sold it at another close price, i.e. a total of exactly two transactions.
You cannot sell a stock before it has been purchased. Your solution can allow buying and selling on the same trading_date (i.e. profit or loss of $0 is always, by definition, an available option); however, for some bonus points, you may write a more general solution for this problem that requires you to hold the stock for at least N days.
This problem should be done in SQL.
Example:
Consider the following table:
INSERT INTO stock VALUES
('2015-06-01', 41),
('2015-06-02', 43),
('2015-06-03', 47),
('2015-06-04', 42),
('2015-06-05', 45),
('2015-06-08', 39),
('2015-06-09', 38),
('2015-06-10', 41);
The biggest profit you can make is $6, and the smallest profit is -$9 (i.e. a loss of $9).
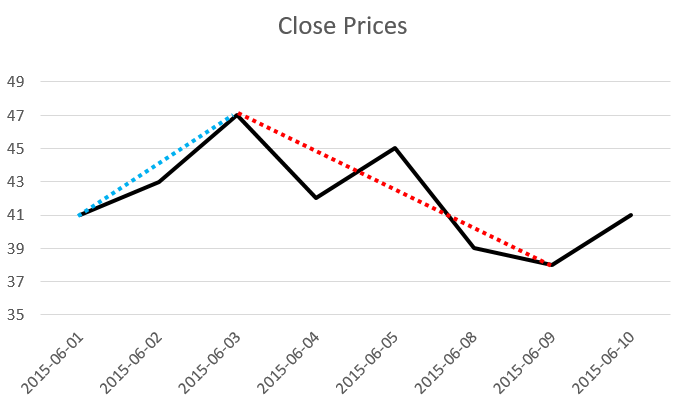
Stay up here to think about the problem for a bit and try to solve it, or scroll down for the answer.
Why This Problem is Cool
- It’s a question about stocks and time series that tests your algorithmic thinking in a programming language of the interviewer’s choice (in this case, SQL). That’s to say: it covers a lot of bases! It’s a perfect screening or whiteboarding question for many quant finance jobs, and it’s still a great problem for many jobs that have little or nothing to do with finance.
- (Minor spoiler) This problem has (broadly) two acceptable answers, but there is a good way and a bad way to implement these. (I’m sure you can guess the bad way by the title of the blog post.)
- (Minor spoiler) Sneaky tricks required to get to the solution sometimes make for cool problems. For example, the previous post in this series of SQL problems had a sneaky solution. But sometimes it’s nice to do some “honest” problems, and this one is very honest.
Writing the Bad Solution in Pseudo-Code (aka Python)
import pandas as pd
data = [
['2015-06-01', 41],
['2015-06-02', 43],
['2015-06-03', 47],
['2015-06-04', 42],
['2015-06-05', 45],
['2015-06-08', 39],
['2015-06-09', 38],
['2015-06-10', 41]
]
df = pd.DataFrame(data, columns=['date', 'price'])
Basically, you want to find a big number and a small number in the data, but the constraint is that the big number has to happen before the small number to measure the lowest profit, and vice-versa for the biggest profit. Very simple.
Many of you probably already have a good idea of what a really bad solution would look like: For each date X, look at all the dates up to and including X and take all of the differences. Any time you see a difference that’s higher than the previous high, or lower than the previous low, save that value. Then at the end, see what the values you saved are. (Also to initialize the max and min stored values, you want to start with the literal worst case scenarios possible.)
This is a quadratic time solution, and it is therefore a bit slow. The upside to this solution is that it’s trivially easy to implement the bonus points into the solution.
Procedural Solution #1
max_profit = df['price'].min() - df['price'].max()
min_profit = df['price'].max() - df['price'].min()
N = 0 # bonus points!
for i in range(len(df)):
for j in range(len(df[:i]) + 1 - N):
max_profit = max(max_profit, df['price'].iloc[i] - df['price'].iloc[j])
min_profit = min(min_profit, df['price'].iloc[i] - df['price'].iloc[j])
print('max:', max_profit)
print('min:', min_profit)
There is actually a way to get this into linear time: save each previous maximum and minimum price. If the 5th value in the time series is the lowest across all time, then every possible highest profit that could occur past the 5th value must include the 5th value. The reverse is true for lowest profits.
Getting the bonus points just requires adding an offset of N days to the running max and min prices.
Procedural SOLUTION #2
running_max_price = df['price'].min()
running_min_price = df['price'].max()
max_profit = df['price'].min() - df['price'].max()
min_profit = df['price'].max() - df['price'].min()
N = 0 # bonus points!
for i in range(len(df)):
if i >= N:
running_max_price = max(running_max_price, df['price'].iloc[i-N])
running_min_price = min(running_min_price, df['price'].iloc[i-N])
max_profit = max(max_profit, df['price'].iloc[i] - running_min_price)
min_profit = min(min_profit, df['price'].iloc[i] - running_max_price)
print('max:', max_profit)
print('min:', min_profit)
These are technically correct solutions, and they’ve helped us frame our thinking, but these sort of for-loop solutions are not optimal, especially for SQL. We will need to translate this solution into something more suitable for SQL.
Set-Based Problem-Solving
Time for a quick intermission.
This is more than just a neat SQL problem; there’s also a very important lesson here that I’ll demonstrate shortly:
If you’re using procedural approaches to solve a query-based problem within a relational database, you’re probably doing something wrong!
A procedural approach is a solution that operates line-by-line, object-by-object. For-loops are a quintessential example of a procedural approach: instead of solving in one big operation, the procedural solution treats the problem as a series of small operations to be iterated out.
There are a few common cases where it makes sense to use for-loops in code that interacts with a relational database, such as performing a set of operations on each column from a list of column names, or re-running a model on various sets of training data. But once you venture outside things like this and you’re still using for-loops, be extremely careful.
Most of the time that you think you may need to loop through a table to solve a problem, you actually don’t. To write better code and better solutions, you must figure out how to make “set-based solutions” instead, i.e. solutions that use joins and unions to surpass the procedures commonly utilized in typical, non-data-related programming. The for-loop solutions can be absolute hell to run, and they totally beat the purpose of using powerful structures like DataFrames and SQL tables to begin with; you might as well be using a list for all it matters.
A generic (if somewhat cryptic) word of advice for finding a set-based solution is to identify whether your procedural solution is isomorphic to some operation on a bounded curve. To do that, we can identify the constraints imposed by the for-loops, and figure out what those constraints mean in the context of a set-based solution.
As you might expect, both the quadratic time approach (solution #1) and the linear time approach (solution #2) have corresponding set-based solutions, obviating the procedural solution:
- Maximizing profit in solution #1 is isomorphic to finding
, subject to
and
.
- Maximizing profit in solution #2 is isomorphic to finding
subject to
.
The boundaries here are created by the rules of stocks: effectively, you can’t sell a stock before you buy it, so that logic is enforced in the first solution with 
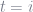

The Real SQL Solutions
Armed with the knowledge that we can transform this for-loop seeming problem into a constrained optimization problem, we are ready for the real solutions.
For the first solution, basically you want a table full of pairs of stock prices (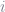

To properly get bonus points, you have to translate the trading_date column into a RANK() so you can then adjust by N trading days. To make this easier to run in all versions of SQL, the answer does not use DECLARE for N; you can adjust the holding period in the 15th row.
Real SOLUTION #1
WITH
sp (price, date_index) AS (
SELECT
price,
RANK() OVER (ORDER BY trading_date)
FROM stock
),
cart_join (buy_price, sell_price, bd, sd) as (
SELECT
a.price,
b.price,
a.date_index as buy_date,
b.date_index as sell_date
FROM sp as a, sp as b
WHERE (buy_date + 0 <= sell_date)
)
SELECT
MAX(sell_price - buy_price) as max_profit,
MIN(sell_price - buy_price) as min_profit
FROM cart_join
Likewise, the other procedural solution can be expressed as a set-based solution. Similar to the procedural solution, I’ll be implementing the N minimum holding days via offsetting, which is implemented with a LAG() window function on on rows 13-14.
REAL SOLUTION #2
WITH
indices (price, trading_date, running_max, running_min) AS (
SELECT
price,
trading_date,
MAX(price) OVER (ORDER BY trading_date ROWS UNBOUNDED PRECEDING),
MIN(price) OVER (ORDER BY trading_date ROWS UNBOUNDED PRECEDING)
FROM stock
),
indices_offset (price, running_max, running_min) AS (
SELECT
price,
LAG(running_max, 0) OVER (ORDER BY trading_date),
LAG(running_min, 0) OVER (ORDER BY trading_date)
FROM indices
)
SELECT
MAX(price - running_min) as max_profit,
MIN(price - running_max) as min_profit
FROM indices_offset
And that’s it!
The transformation from a procedural solution to a set-based solution isn’t just something that’s good in SQL. Set-based solutions can and should be implemented over procedural solutions in Pandas, Stata, and R as well. I will leave it as an exercise to curious readers to see how you can implement set-based solutions in Pandas without the use of a for-loop.
Now, armed with the knowledge of how to transform procedural solutions into set-based solutions, go back into your code and ask yourself, “did I really need that for loop?” The results may shock you.

You must be logged in to post a comment.